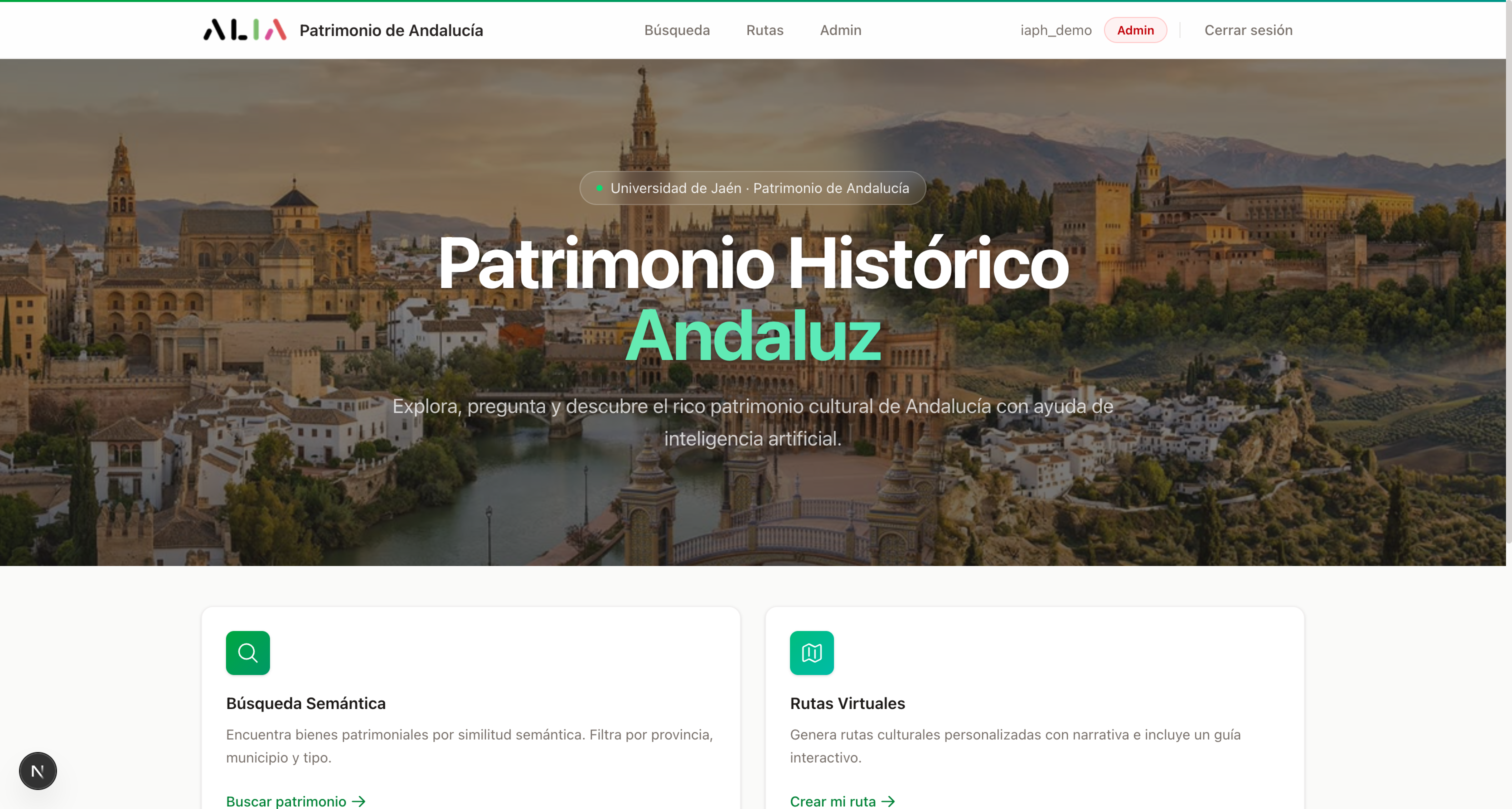
ALIA Patrimonio de Andalucía is a conversational AI platform built for the Instituto Andaluz de Patrimonio Histórico (IAPH). It makes over 134,000 cultural heritage records — buildings, artworks, intangible traditions, and landscapes — accessible through natural language. Users can search semantically, generate personalized virtual routes, and interact with an AI guide, all powered by a custom RAG (Retrieval-Augmented Generation) pipeline.
I developed this platform as part of the ALIA initiative, a national project funded by the Spanish government and the EU’s NextGenerationEU program. The system is designed to serve researchers, heritage professionals, and the general public.
System architecture
The platform runs as four containerized services orchestrated with Docker Compose:
React 19 + TypeScript
Tailwind CSS v4 + Zustand] end subgraph Backend API[FastAPI Backend
Python 3.11
Hexagonal Architecture] end subgraph AI Services EMB[Embedding Service
FastAPI
MrBERT / Qwen3-Embedding] LLM[LLM Service
vLLM + bitsandbytes
Salamandra-7b / ALIA-40b] end subgraph Storage DB[(PostgreSQL 16
+ pgvector)] end U -->|HTTPS| FE FE -->|REST API| API API -->|Encode queries & chunks| EMB API -->|Generate responses| LLM API -->|Vector + text search| DB
The backend follows a strict hexagonal architecture with 10 bounded contexts, each implementing the same four-layer pattern:
FastAPI routers
Pydantic schemas] --> B[Application Layer
Use cases
DTOs & orchestration] B --> C[Domain Layer
Entities & value objects
Ports — abstract interfaces] D[Infrastructure Layer
SQLAlchemy ORM
HTTP adapters] -.->|implements| C end
The 10 bounded contexts are: documents (ingestion & chunking), RAG (retrieval pipeline), chat (conversational sessions), routes (virtual itineraries), heritage (asset catalog), search (faceted queries), accessibility (text simplification), auth (JWT authentication), feedback (user ratings), and shared (cross-cutting ports).
RAG pipeline
The core intelligence is a hybrid RAG pipeline. Each user query goes through six stages before an answer is generated:
history?} R -->|Yes| QR[Query Reformulation
LLM rewrites multi-turn
query into standalone question] R -->|No| E QR --> E[Embedding
MrBERT 768-dim /
Qwen3-Embedding 1024-dim] E --> VS[Vector Search
pgvector cosine similarity
k=20 candidates] E --> TS[Text Search
PostgreSQL tsvector
Spanish stemming, k=20] VS --> RRF[Reciprocal Rank Fusion
1.5× weight on text matches] TS --> RRF RRF --> RF[Relevance Filter
Discard chunks with
score above 0.50 threshold] RF --> ABS{All chunks
filtered?} ABS -->|Yes| ABR[Abstention
Insufficient information response] ABS -->|No| RK RK[Reranking
Neural: Qwen3-Reranker
Heuristic: title match,
coverage, position] --> CTX[Context Assembly
Top-k chunks
max 6000 chars] CTX --> GEN[LLM Generation
Salamandra-7b / ALIA-40b / Gemini
T=0.3, max_tokens=512] GEN --> ANS[Answer with
source citations]
The abstention mechanism is critical: if all retrieved chunks fall below the relevance threshold, the system responds with an “insufficient information” message instead of hallucinating. This is especially important in a heritage context where factual accuracy matters.
AI models
The platform supports multiple models at each stage of the pipeline, allowing flexibility between accuracy, speed, and hardware requirements:
Embedding models
| Model | Parameters | Dimensions | Pooling | Languages | Use case |
|---|---|---|---|---|---|
| BSC-LT/MrBERT | 308M | 768 | Mean | 35+ | Default — optimized for Spanish heritage text |
| Qwen/Qwen3-Embedding-0.6B | 600M | 1,024 | Last-token | 100+ | Alternative — higher dimensionality, multilingual |
Both models run on a dedicated FastAPI embedding microservice. MrBERT is the default choice as it was pre-trained on Spanish corpora by the Barcelona Supercomputing Center, making it particularly effective for heritage terminology.
Reranking model
| Model | Parameters | Type | Purpose |
|---|---|---|---|
| Qwen/Qwen3-Reranker-0.6B | 600M | Cross-encoder | Neural reranking of retrieved chunks |
The reranker operates as a second-stage filter, scoring each (query, chunk) pair with a cross-encoder. It works alongside four heuristic signals: base retrieval score, title match bonus, query term coverage, and chunk position weighting.
LLM decoders
| Model | Parameters | Quantization | VRAM | Context | Use case |
|---|---|---|---|---|---|
| BSC-LT/salamandra-7b-instruct | 7B | None (FP16) | 14 GB | 8K tokens | Default — Spanish-first, fast inference |
| BSC-LT/ALIA-40b-instruct-2601 | 40.4B | GPTQ 4-bit | 32 GB | 163K tokens | Advanced — higher quality, longer context |
| Gemini 2.0 Flash Lite | — | API | 0 (cloud) | 1M tokens | Cloud fallback — no GPU required |
Salamandra-7b is the primary decoder, developed by BSC specifically for Spanish language tasks. It runs on a single GPU via vLLM with continuous batching. ALIA-40b is a larger model from the same family, quantized to 4-bit GPTQ for deployment on 32 GB GPUs, offering higher quality generation at the cost of throughput. Gemini serves as a zero-GPU fallback for development or cost-sensitive deployments.
All models are configured through environment variables, making it possible to swap between configurations without code changes.
Data corpus
The platform indexes the full IAPH heritage catalog from four parquet datasets:
| Dataset | Records | Examples |
|---|---|---|
| Patrimonio Inmueble | ~30,000 | Buildings, archaeological sites, monuments, fortifications |
| Patrimonio Mueble | ~100,000 | Paintings, sculptures, documents, liturgical objects |
| Patrimonio Inmaterial | ~2,000 | Festivities, traditional trades, oral traditions |
| Paisaje Cultural | 117 | Landscapes with historical-cultural significance |
Each record is chunked, embedded, and stored in PostgreSQL with pgvector for vector similarity search. The text search index uses Spanish stemming (spanish tsvector configuration) for morphological matching.
Semantic search
The search interface lets users query the full heritage catalog in natural language. The system automatically detects entities in the query — provinces, municipalities, heritage types — and offers to apply them as filters through a clarification panel.

Search results showing entity detection, relevance scores, and the detail panel with images and map
Results display as cards color-coded by heritage type (green for buildings, purple for artworks, teal for intangible heritage, blue for landscapes). Each card shows a relevance score computed from the hybrid search fusion. Clicking a result opens a detail panel with an image gallery, interactive Leaflet map, and structured metadata including styles, periods, and protection status.
Provinces, municipalities,
heritage types] ED --> CL[Clarification Panel
Apply as filters?] CL --> HY[Hybrid Search
Vector + Text] HY --> RS[Ranked Results
Color-coded cards] RS --> DP[Detail Panel
Gallery, map, metadata]
Virtual routes
Users can describe a route in natural language — “Renaissance monuments in Úbeda and Baeza” or “Cave paintings in Jaén” — and the system generates a personalized itinerary with AI-written narrative connecting the stops.

Route generator with entity-aware input and grid of previously generated routes
The route generation pipeline extracts entities from the user’s description, queries the RAG system for relevant heritage assets, and then uses the LLM to compose a structured narrative:
Places, heritage types,
themes] EX --> RAG[RAG Retrieval
Find matching heritage
assets] RAG --> SE[Stop Selection
2-15 stops
ranked by relevance] SE --> NR[Narrative Generation
LLM writes introduction,
transitions & descriptions] NR --> RT[Structured Route
Cover, metadata,
interleaved stops + narrative] RT --> IG[Interactive Guide
Contextual chatbot
for route Q&A]
Each route includes a cover image, metadata (province, number of stops, estimated duration), and an interleaved layout of narrative sections and stop cards:

Route detail showing the header, AI-generated introduction, and the first stop with its narrative
A floating chat button opens an interactive guide — a chatbot contextualized to the current route that can answer questions about any of the heritage assets along the way.
Accessibility
The platform includes a Lectura Fácil (Easy Reading) module that simplifies heritage texts following ILSMH guidelines, making content accessible to people with cognitive disabilities. Users can choose between two simplification levels:
- Basic — maximum simplicity, short sentences, common vocabulary
- Intermediate — simplified but retaining more detail, suitable for the general public
The simplification is performed by the LLM with a specialized prompt that enforces the ILSMH readability rules.
Tech stack
| Layer | Technologies |
|---|---|
| Backend | Python 3.11, FastAPI, SQLAlchemy 2.0 (async), Alembic, asyncpg, pgvector, Pydantic 2, bcrypt, PyJWT |
| Frontend | Next.js 16, React 19, TypeScript 5, Tailwind CSS v4, Zustand 5, react-leaflet, react-markdown |
| Embedding | MrBERT (BSC-LT, 308M), Qwen3-Embedding-0.6B (Qwen) |
| Reranking | Qwen3-Reranker-0.6B (cross-encoder) |
| LLM inference | vLLM + bitsandbytes, Salamandra-7b-instruct (BSC), ALIA-40b-instruct GPTQ (BSC), Gemini 2.0 Flash Lite |
| Database | PostgreSQL 16 + pgvector extension |
| Infrastructure | Docker Compose, Google Cloud Run, Google Cloud IAM, GitLab CI/CD |
Key numbers
| Metric | Value |
|---|---|
| Heritage records indexed | 134,000+ |
| Bounded contexts | 10 |
| API endpoints | 40+ |
| Test functions | 307+ |
| Alembic migrations | 11 |
| Embedding models supported | 2 (MrBERT, Qwen3-Embedding) |
| LLM backends supported | 3 (Salamandra-7b, ALIA-40b, Gemini) |
| Heritage types covered | 4 (Inmueble, Mueble, Inmaterial, Paisaje Cultural) |
| Andalusian provinces covered | 8 |
ALIA Patrimonio de Andalucía is developed within the framework of the ALIA initiative, funded by the Spanish Ministry of Digital Transformation and the EU’s NextGenerationEU program, in collaboration with the Barcelona Supercomputing Center (BSC) and the University of Jaén (SINAI research group).
